
티스토리 뷰
개정 후 기출로 본 예상 문제 형식
1.SQL문 작성
반드시 한문제는 출제 될 듯!
실수하지 않는것이 관건이고 난이도에 따라 3~12점까지 배점분포가 넓다.
2.용어 단답식 (4~5개 출제가능/3~4점)
현재까지는 기출된 용어에서 100% 출제되었으므로 출제된 용어를 반복학습!
3.용어 서술형 (5~10점)
배점이 크고... 어디서 나올지 모르겠다:)
기출용어중에서 중요한 용어를 설명하라고 하지 않을까 싶다.
작년 3차와 올해 1차시험
현재까지는 기출된 용어에서 100% 출제되었으므로
출제된 용어를 반복학습하는 것이 좋겠다
2017년 1회 기출 가채점 답안!
1) SQL
INSERT INTO 학생 Values(98170823, '한국산', 3, '경영학개론', '?-1234-1234'); (배점 3점)
- INTO 학생(속성명1,속성명2,...) 처럼 속성명을 다 입력해도 됩니다.
- Values 에서 s 빠지면 안됩니다. (오류 발생하는 문장이므로 부분 점수 없습니다.)
- 문자형은 싱글(홑)따옴표 입력 : 4강
2) 용어
- Cascade (배점 4점): SQL 문장에서 괄호 채우기 4강 16년1회 기출
- (1) Drill Down 또는 Drill-Down 또는 Roll Down 또는 Roll-Down
(2) Pivoting (배점 6점, 각 3점) 5강 14년3회 기출
- 트랜잭션 일관성, 영속성 서술형 (배점 10점): 각 5점 6강 공단 공개 문제
- Trigger (배점 2점) 6강 16년3회 기출
출처: 기사퍼스트
기출년도 | 용어 | ||||
2011 | 1 | Shared Data, content reference, MARC, 상호운용성, MD | 1.데이터베이스의 개요 | ||
2 | 다치 종속성, 무손실분해, 자연 조인, 조인 종속성, 후보키 | 2.데이터모델링 | |||
3 | 트리거, 이벤트, MAX, 선분 이력 , 변경 | 5.데이터베이스실무 | |||
2012 | 1 | 데이터웨어하우스, 관계형데이터베이스, MOLAP, HOLAP, 데이터 큐브 | 5.데이터베이스실무 | ||
2 | id, name, CASCADE, VIEW, INDEX | 3.관계데이터베이스 언어 | |||
3 | X->Y, Anomaly, 부분 함수적 종속, 2NF, 이행 함수적 종속 | 4.정규화 | |||
2013 | 1 | 함수적 종속, A->C, 4NF, 복합키, 다치종속성 | 4.정규화 | ||
2 | 관계해석, 셀렉트, 프로젝트, Division, Natural | 2.데이터모델링 | |||
3 | Big data, Cloud | 5.데이터베이스실무 | |||
2014 | 1 | 메타데이터, Data Warehouse, 다차원, OLAP, Data Mining | 5.데이터베이스실무 | ||
2 | 제약조건, Mapping Rule, 기본키, 식별, 비식별 | 2.데이터모델링 | |||
3 | Data Mart, Drill-down, Pivoting, Slicing, Dicing, HOLAP | 5.데이터베이스실무 | |||
2015 | 1 | Big data, DSMS, Anomaly, 부분함수적종속, 2NF | 4.정규화 5.데이터베이스실무 | ||
2 | Tunning, Locking, Selectivity, Clustered, Non-Clustered | 5.데이터베이스실무 | |||
3 | 운영데이터, Continuous Evolution, MARC, 상호운용성, MDR | 1.데이터베이스의 개요 | |||
2016 | 1 | 관리기법,제약조건,Reference,CASCADE,RESTRICT | 2.데이터모델링 | ||
2 | MetaData,DataWarehouse,다차원,OLAP,DataMining | 5.데이터베이스실무 | |||
3 개정 후 | 기본키/주키,외래키/참조키,접수종류,무결성,Project | ||||
2017 | 1 개정 후 | CASCADE ,Drill Down / Roll Down , Pivoting (배점 3점) Trigger (배점 3점) 서술형: 트랜잭션의 ACID중 일관성 영속성 설명하기 | |||
다음은 2과목 데이터베이스의 개요☆☆
2과목
데이터베이스
ch1. 데이터베이스의 개요
ch2. 데이터모델링
ch.3 관계 데이터베이스 언어
ch.4 정규화
ch.5 기타 데이터베이스 실무 응용
각 주제별로 출제되는 용어를 정리해보았다!
개정이전까지는 주제별로 뭉탱이로 출제되었었기 때문...
ch1. 데이터베이스의 개요/ 메타데이터
2015년 3회 기출 / 2011년 1회 기출
Operational Data 운영데이터 (2015년 3회 기출)
중복을 최소화하고 여러 사람이 공유함에 있어 문제가 발생하기 않도록
관리를 필요로하는 데이터로 이용가치가 있는 데이터의 집합
Shard Data 공용데이터 (2011년 1회 기출)
여러 사용자와 다수의 응용 시스템이 공유할 수 있도록 만든 데이터의 집합
※ 데이터베이스의 정의는 다음과 같다.
Integrated Date : 하나의 주제에 따라 중복을 최소한 한 데이터의 집합
Stored Date : 사용자나 응용시스템이 필요시 언제든지 이용할 수 있도록 저장된 데이터의 집합
Shared Data
Operationa Data
Continuous Evolution 계속적인 변화(진화)
항상 최신정보를 유지할 수 있도록 삽입, 삭제, 갱신이 이루어짐
Content Reference 내용에 의한 참조
데이터베이스 환경 하에서 데이터 참조는 데이터베이스에 저장된 레코드들의 위치나 주소에 의해서가 아니라
사용자가 요구하는 데이터 내용, 즉 데이터 값에 따라 참조된다는 것이다.
※DB는 최소한 다음과 같은 특성을 가져야 그 기능을 최대한으로 발휘 할 수 있다.
Continuous Evolution 진화
Concurrent Sharing 동시공유 , 여러 사용자가 동시에 접근하여 이용
Real Time Accessibility 실시간 접근성, 질의(SQL)에 대해 실시간 처리 및 응답
Content Reference 내용에 의한 참조
Redundancy Minimize 동일 데이터의 중복성을 최소화 해야함
DBMS (Database Management system)
기존 파일 시스템의 문제점인 데이터의 종속성, 중복성 의 최소화를 위해 등장.
사용자와 데이터베이스의 중계 역할.
데이터베이스의 내용을 조작, 정의, 제어(DDL,DML,DCL) 할 수 있음.
모든 사용자나 응용프로그램들이 데이터베이스를 공유할 수 있도록 관리 운영해주는 소프트웨어 시스템이다.
중복성 : 동일한 데이터가 중복됨으로 발생되는 비효율성
종속성 : 하나의 데이터가 삭제, 변경됨에 따라 다른 데이터가 원치 않게 영향을 받는 성질
시스템카탈로그 = 데이터 사전
데이터 베이스에 저장되어 있는 테이블, 인덱스, 뷰, 제약조건, 사용자 등 개체들에 대한 정보와 정보들 간의 관계를 저장한 것으로 그
자체가 하나의 작은 데이터베이스 이다.
시스템 카탈로그에 저장된 데이터를 메타 데이터라고 한다.
메타데이터
데이터에 관한 구조화된 데이터로, 다른 데이터를 설명 해 주는 데이터. 속성정보라고도 한다.
대량의 정보 가운데에서 찾고 있는 정보를 효율적으로 찾아내서 이용하기 위해 일정한 규칙에 따라 콘텐츠에 대하여 부여되는 데이터이다.
여기에는 콘텐츠의 위치와 내용, 작성자에 관한 정보, 권리 조건, 이용 조건, 이용 내력 등이 기록되어 있다.
컴퓨터에서는 보통 메타데이터를 데이터를 표현하기 위한 목적과 데이 터를 빨리 찾기 위한 목적으로 사용하고 있다.
☆★☆★MARC (Machine Readable Cataloging 기계가독목록 )☆★☆★
컴퓨터가 목록 데이터를 식별하여 축적, 유통할 수 있도록 코드화한 일련의 메타데이터 표준 형식.
컴퓨터를 통해 목록 데이터를 효율적으로 처리하기 위해서는 모든 데이터를 컴퓨터가 인식할 수 있는 형식으로 변환시켜, 이를 정형화된 형식으로 배열해야 하는데, MARC는 이와 같이 컴퓨터가 목록 데이터(저자,서명,형 태,출판사항 등)를 식별하여 축적 · 유통할 수 있도록 코드화한 일련의 메타데이터 표준 형식이다.
MARC는 도서관의 자동화된 목록 작성에 사용되는 대표적인 메타데이터 형식 표준으로 도서관 간에 목록 레코드 를 상호 교환하기 위해 미국 의회 도서관(Library of Congress, LC)이 개발하였다.
상호운용성
서로 다른 메타 데이터를 사용하는 시스템들이 각각의 메타 데이터를 이해할 수 있게 함으로써 정보를 교환, 이용할 수 있게 함
☆★☆★MDR(MetaData Registry, 메타데이터 등록소)☆★☆★
메타데이터의 등록과 인증을 통하여 메타데이터를 유지 ㆍ관리하며, 메타데이터의 명세를 공유하는 레지스트리.
메타데이터를 사용하여 데이터에 대한 접근과 사용을 촉진하고 메타데이터가 설명하는 특징에 따른 데이터의 조작을 가능하게 한다.
스키마(Schema)(16년 1회 산업기사)
스키마는 데이터베이스의 전체적인 구조와 제약조건에 대한 명세를 기술, 정의한 것을 말한다.
내부스키마 : 물리적 저장장치 관점, 기계의 관점 2진수
개념스키마 : 논리적 관점, 사람이 이해할 수 있는 전체적 데이터구좉
외부스키마 : 사용자의 관점
ch2. 데이터모델링
2014년 2회 기출 / 2013년 2회 기출/2012년 2회
데이터 아키텍쳐
기업의 데이터 측면에서 기업 시스템을 처음부터 끝까지 시스템의 본질인 데이터를 구조적, 체계적으로 관리하고 설계하는 모든과정
개념적 설계 (ER모델을 사용)-> 논리적 설계 -> 물리적 설계
※관계형 데이터베이스의 릴레이션구조 관련 용어
테이블 (릴레이션) = 표 : 자료 저장 형태가 2차원 구조의 테이블로 표현, ER에서의 개체에 해당함
튜플 (Tuple)= 행, Row
속성 (Attribute) = 열, Column ․
릴레이션 스키마(스킴,내연) : 속성 이름들 (릴레이션 틀,구조) ․
릴레이션 인스턴스(외연) : 튜플들의 집합 (릴레이션 실제값) ․
도메인 (Domain) : 한 속성에 나타날 수 있는 값들의 범위(집합) ․
차수 (Degree): 속성들의 수 ․
카디날리티 (cardinality) : 튜플들의 수 ․
널 (Null) : "해당없음" 등의 이유로 정보 부재를 나타내 기 위해 사용 하는 특수한 데이터 값
※릴레이션의 특징
1. 튜플은 모두 상이하다,
2. 튜플은 유일하며 순서에는 의미가 없다
3. 속성들 간의 순서는 의미가 없다
4. 속성은 원자값으로 구성되며 분해가 불가능하다.
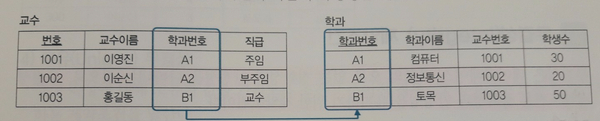
Mapping Rule
개념적 데이터 베이스 모델링에서 도출된 개체에 관계형 데이터 베이스 이론을 적용하여 릴레이션 스키마로 변환하는 것
(개체 - 릴레이션, 속성- 컬럼, 식별자 - 기본키, 관계 - 외래키)
ER-Model로 표현된 단순한 개체와 속성을 릴레이션으로 표현한 경우
개념적 설계 단계에서 ER로 표현된 학번, 성명, 학과, 연락처 속성으로 구성된 '학생' 개체를 논리적 설계 단계에서 학번, 성명, 학과, 연락처 속성으로 구성된 '학생' 릴레이션으로 구현한다.
교차엔티티
다대다 관계의 E-R 모델을 릴레이션으로 표현하느 경우 하나의 릴레이션을 더 만들게 된다.
키(Key)
관계 데이터베이스에서 튜플을 식별하기 위해 사용되는 속성이나 속성의 집합, 데이터베이스의 참조 또는 검색시에 사용된다.
특정 조건에 맞는 튜플을 구분할 수 있는 단일 속성 또 는 속성 그룹을 말함.
1) 후보키 : 한 릴레이션 내에 있는 모든 튜플들을 유일 하여 식별할 수 있는 하나 또는 몇 개의 애트리뷰트 집합 (최소 슈퍼키 : 유일성 + 최소성)
2) 기본키 : 후보키(유일성과 최소성 만족) 중에 특별히 선택 된 키 (중복될 수 없고 NULL값 올 수 없음)
3) 대체키 : 후보키 중에서 기본키를 제외한 속성들
4) 외래키 : 어떤 R에서 다른 R을 참조할 때 참조 기준 이 되는 속성으로서 참조하고자 하는 R의 기본키와 동일
5) 슈퍼키 : 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키를 말한다. (유일성)
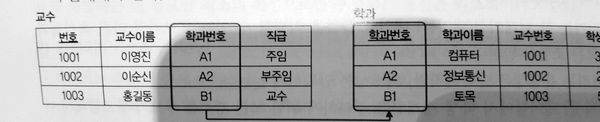
식별 관계
실선으로 표시, 부모 엔티티의 주 식별자가 자식 엔티티의 외래 식별자이자 동시에 주 식별자가 되는 관계
외래키가 기본키인 경우
비식별 관계
점선으로 표시, 부모 엔티티의 주 식별자가 자식 엔티티의 외래 식별자이자 일반 속성으로 존재하는 독립적 관계
외래키가 일반 속성 키인 경우

제약조건
데이터베이스에 저장되는 데이터의 정확성을 보장해주기 위해 키를 이용하여 입력되는 데이터에 제한을 주는 것을 의미한다.
무결성
데이터베이스 자료의 오류없는 정확성과 안정성을 나타내는 것으로, 무결성 제약조건은 정확성과 안정성을 위한 제약 조건이다.
기본키와 관련된 무결성 제약조건 : '개체무결성'
외래키와 관련된 무결성 제약조건: '참조무결성'
※ 무결성의 종류
- 개체 무결성 : 개체 식별을 위해 오류가 없도록 하기위한 제약조건 (기본키는 NULL값이 올 수 없고 중복 될 수 없음)
- 참조 무결성 : 참조 릴레이션의 기본키와 같아야 하는 제약조건외래키는 NULL 값 가능
참조무결성의 제약조건을 지키기 위한 두가지 방법
CASCADE : 삭제할 요소가 참조중이더라도 삭제가 이루어진다.
RESTRICT: 삭제할 요소가 참조중이면 삭제하지 않는다.
- 도메인 무결성 : 속성 값의 범위가 정의된 경우, 범위를 준수해야하는 제약조건
- 고유 무결성 : 특정 속성의 고유값 조건 -> 속성 값은 모두 달라야하는 제약조건
- NULL 무결성 : 특정 속성 NULL 올 수 없음 제약조건
- KEY 무결성 : 한 릴레이션에는 최소한 하나의 키 존재 제약조건
셀렉트 Select(13년 2회)
릴레이션에서 조건을 만족하는 수평적 부분집합(튜플)을 구하기 위한 연산을 말한다.
프로젝트 Project(13년 2회)
프로젝트 연산은 릴레이션에서 수직적 부분집합을 구하는 연산으로 원하는 속성만 추출하기 위한 연산.
조인 Join(11년 2회)
두 테이블로부터 조건에 맞는 관련된 튜플들을 하나의 튜플로 결합하여 하나의 테이블로 만드는 연산.
- 동일조인 : 관계연산자 '=' 연산자만을 사용한다. 가장 기본이 되는 조인이며, 두 테이블의 모든 속성을 합한 하나의 테이블 구조로 만들어진다.
(중복이 되는 속성도 모두 표현한다)
- 자연조인(natural):동일 조인한 결과에서 중복되는 속성을 제거하여 표현한다. (기사 12년2회, 11년 2회)
- 외부조인:조건에 맞지 않는 튜플도 결과 테이블에 포함시켜 조인하는 방법, 해당 자료가 없으면 NULL값이 된다.
-세타조인:'=' 이외의 연산자를 이용한 조건 수식표현
디비전 Division(기사13년 2회)
A DIVISION B 는 B테이블의 조건을 만족하는 튜플들을 테이블 A에서 추출하는 연산이다.
관계대수
-절차적언어(절차중심): 원하는 정보를 ‘어떻게’ 유도하는 가를 연산자와 연산규칙을 이용하여 기술
① SELECT (σ) - 릴레이션에서 주어진 조건을 만족하는 튜플들을 검색 하는 것으로 기호는 그리스 문자의 시그마(σ)를 이용. (행, 수평적 연산)
σ 조건 (R)
② PROJECT (π) - 릴레이션에서 주어진 조건을 만족하는 속성들을 검색 하는 것으로, 기호는 그리스 문자의 파이(π)를 이용. (열, 수직적 연산)
π 속성 (R)
③ JOIN
-두개의 릴레이션A와 B에서 공통된 속성을 연결하는 것
학생⋈학번=학번 성적
-A*B(NATURAL JOIN, 자연조인): 공통 속성값 제거
-A⋈B(EQUI JOIN,동등조인): 공통 속성값 중복
④ DIVISION (÷)
- 나누어지는 릴레이션인 A는 릴레이션 B의 모든 내용을 포함한 것이 결과 릴레이션이 된다
관계해석
관계해석은 릴레이션에서 결과를 얻기 위한 과정을 표현하는 것으로 연산자 없이 정의하는 방법을 이용하는 비절차적 언어이다.
튜플관계 해석과 도메인 관계 해석이 있다.
ch3.관계데이터베이스 언어
2017년1회/2012년 2회
VIEW (06년 1회)
뷰는 하나이상의 테이블로 이루어진 가상테이블로 처리과정중의 중간 내용이나 기본테이블 중 일부 내용을 검색해 보여주거나 별도로 관리하고 있는 임시 테이블이다.
실제 물리적으로 기억공간을 차지 하지 않는다.
시스템 카탈로그(10년 4회)
데이터베이스에 저장되어있는 테이블,인덱스, 뷰, 제약조건, 사용자 등 개체들에 대한 정보와 정보들 간의 관계를 저장한 것으로 그 자체가 하나의 작은 데이터 베이스이다.
ch.4 정규화
2015년 1회/2013년 1회/2012년 3회/2011년
Anomaly(이상)
데이터베이스의 논리적 설계 시 하나의 릴레이션에 많은 속성이 존재하여, 데이터의 중복과 종속으로 인해 발생되는 무제점.
1) 갱신이상 : 반복된 데이터 중에 일부만 수정하면 데이터의 불일치가 발생
2) 삽입이상 : 불필요한 정보를 함께 저장하지 않고는 어떤 정보를 저장하는 것이 불가능
3) 삭제이상 : 유용한 정보를 함께 삭제하지 않고는 어떤 정보를 삭제하는 것이 불가능
함수적종속(15년 1회,13년 1회)
릴레이션에서 'A -> B' A의 값이 B 값을 결정할때 종속이라고 한다.
A값을 알면 B값을 알 수 있거나 A값에 따라 B의 값이 달라진다. B는 A에 함수적으로 종속되었다고 본다.
A - 결정자, B - 종속자
1.완전 함수적 종속 (15년1회, 12년 3회)
릴레이션의 한 속성이 오직 기본키에만 종속이 되는 경우
2.부분 함수적 종속 (15년1회, 12년 3회)
한 속성이 기본키가 아닌 다른 속성에 종속되거나 기본키가 2개 이상의 합성키로 구성
3.이행적 함수적 종속
A->B, B->C 일 때, A->C를 만족하는 관계
A를 알면 B를 알 수 있고 B를 알면 C를 알 수 있을때
정규화(Nomalization)
: 논리적 설계 단계에서 발생할 수 있는 종속으로 인한 이상현상(Anomaly)의 문제점을 해결하기 위해,
속성들 간의 종속 관계를 분석하여 여러 개의 릴레이션으로 분해하는 과정
- 제 1 정규형 1NF
모든 도메인이 원자값이 되도록 분해하는 것
- 제 2 정규형 2NF (2015년 1회)
1NF를 만족하고, 부분 함수 종속 관계를 제거한 것.
- 제 3 정규형
이행적 함수 종속 관계를 제거한것.
- BCNF
후보키가 아닌 결정자 관계를 제거한것.
보이스-코드 정규화 또는 BCNF 정규화란 Boyce-Codd Normal Form의 약자로서, 1974년 Raymond Boyce와 Edgar Codd가 만든 데이터베이스 정규화 형식을 말한다. 관계형 데이터베이스의 릴레이션 R에서 함수 종속성 X→Y가 성립할 때, 모든 결정자 X가 후보키이면 BCNF 정규형이 된다. 즉, 식별자로 쓰이는 속성이 일반속성에 종속되지 않아야 한다. 제3정규화를 통해서도 제거되지 않은 데이터의 중복 문제를 해결해 주기 때문에 일명 ‘제3.5정규화’라고도 부른다.
- 제 4 정규형 4NF (13년 1회 11년 2회)
다치종속 관계를 제거한것.
- 제 5 정규형 (11년 2회)
후보키를 통하지 않은 조인 종속 관계를 제거한 것.
ch.5 기타 데이터베이스 실무 응용
2016년 3회/2015년 2회/ 2014년 3회/2011년 3회
트랜젝션
데이터베이스 내에서 한꺼번에 모두 수행되어야 하는 연산들의 집합
나의 작업 처리를 위한 논리적 작업단위!
트랜젝션 내의 연산은 한꺼번에 처리되어야 하며 그렇지 못한 경우 모두 취소되어야 한다.
트랜젝션의 성질 (ACID) (11년 1회)
① 원자성(Atomicity)(17년1회)
가장 중요 - 모두 반영되거나 아니면 전혀 반영되지 아니어야 된다. (부분 실행 안됨, All or Nothing)
② 일관성(Consistency)
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일 관성 있게 DB 상태로 변환
③ 독립성,격리성(Isolation)
둘 이상의 트랜잭션이 동시에 병행 실행되고 있을 때
또 다른 하나의 트랜잭션의 연산이 끼어들 수 없다.
④ 영속성,지속성(Durability) (17년1회)
트랜잭션의 결과는 영구적으로 반영
COMMIT
트랜잭션이 성공적으로 종료된 후 수정된 내용을 지속적으로 유지하기 위한 연산.
ROLLBACK
트랜젝션이 비정상적으로 수행되었거나 오류가 발생했을 때 수행 작업을 취소하고 이전 상태로 되돌리기 위한 연산.
병행제어(Concurrency Controll)
동시에 여러 개의 트렌젝션이 실행되는 경우를 병행 실행이라고 하는데
이와같이 병행실행시 트랜잭션 간의 격리성을 유지하여 트랜잭션 수행에 문제가 발생되지 않도록 제어하는 것을 병행제어라고 한다.
대표적인 병행제어의 방법으로 로킹(Locking)기법이 있다.
로킹(Locking)(15년 3회)
트랜젝션의 병행실행시 하나의 트랜잭션이 사용하는 데이터베이스 내의 데이터를 다른 트랜잭션이 접근하지 못하게 하는 것을 말한다. 하나의 트랜젝션이 실행될 때는 LOCK을 설정해 다른 트랜잭션이 데이터에 접근하지 못하도록 잠근 후 실행하고, 실행이 완료되면 UNLOCK을 통해 해제한다.
인덱스(Index)
수많은 데이터 중에서 원하는 자료를 빠르고 효율적으로 검색하기 위해서 사용하는 방법
인덱스 기타유형 : 클러스터드 인덱스, 넌클러스터드 인덱스(15년 2회)
Selectivity
인덱스의 키 값당 행의 개수
Clustered
테이블에서 하나의 속성을 기준으로 정렬한 후, 테이블을 재구성하여 인덱스를 만드는 과정.
테이블의 물리적 순서와 인덱스 순서가 동일하다.
Non-Clustered
테이블을 재구성하지 않고 데이터 주소를 이용하여 인덱스를 만들어 주소값을 이용하여 검색하는 방법이다.
기타 데이터베이스 용어
★☆☆★
Tunning
데이터베이스의 성능향상과 사용자의 요구에 따라 빠른 검색을 통한 신속한 서비스 제공, 저장공간의 효율을 향상시키는 등 데이터 베이스의 시스템을 최적화 하기 위해 재조정 하는 것.
업무의 최적화, 하드웨어적인 병목 현상 해결, SQL의 최적화 등 여러가지 개선을 도모. 사용자가 필요한 때에 원하는 정보를 보다 원활하게 제공
Trigger
참조 관계에 있는 두 테이블에서 하나의 테이블에 삽입, 삭제, 갱신 등의 연산으로 테이블의 내용이 바뀌었을 때 데이터의 일관성과 무결성 유지를 위해 이와 연관된 테이블도 연쇄적으로 변경이 이루어 질 수 있도록 하는 것을 말한다.
★☆☆★
DSMS (Data Stream Management System)
데이터 스트림 관리 시스템으로 단순한 실시간 스트림 데이터의 효율적인 처리뿐만 아니라 기존의 DBMS와 결합하여 데이터마이닝이나 데이터웨어하우징 같은 고급 서비스를 사용자에게 제공
Data Warehouse
한 조직이나 사용자의 의사결정에 도움을 주기 위하여, 기간 내의 저장된 대량의 데이터를 공통의 형식으로 변환하여 관리하는 데이터베이스. 데이터 베이스에 축적된 데이터를 공통의 형식으로 변환하여 일원적으로 관리하는 데이터 베이스
Data Mining
데이터 웨어하우스 같은 대량의 데이터에서 실제로 존재하지 않는 정보를 얻어내기 위해 데이터의 상관관계를 통계적 분석, 인공지능 기법등을 통해 통계적 규칙,패턴을 찾아 존재하지 않는 정보를 얻어 내는것(클러스터링 방법, 경향분석방법 등)
Data Mart
특정 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터 웨어하우스
데이터의 한 부분에서 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터 웨어하우스를 말한다.
DataCube
데이터가 여러 차원으로 모델링 되는 것
관계형 데이터베이스
데이터를 열과 행으로 이루어진 이차원의 릴레이션으로 표현하는 데이터베이스의 한 종류
Bigdata
기존 데이터 베이스 관리 도구의 데이터 수집/저장/분석의 역량을 넘어서는 대량의 정형 또는 비정형 데이터 및 이러한 데이터로부터 가치를 추출하고 결과를 분석하는 기술
★☆☆★
OLAP(Online Analytical Processing)
사용자가 직접 데이터베이스 검색과 분석을 통해 문제점이나 해결책을 찾도록 도와주는 분석형 어플리케이션 개념.
온라인 검색을 지원하는 데이터웨어하우스 지원 도구 이며, 이같은 대규모 연산이 필요한 질의를 다차원 구조 분석 기법을 통해 고속으로 지원한다.
MOLAP (Multidimensional OLAP)
다차원 데이터베이스에 기반한 OLAP 아키텍쳐. 결과값을 다차원 배열로 저장하여 다차원의 데이터 베이스 큐브 형태의 데이터 뷰로 구성하여 다양한 분석을 할 수 있도록 지원.
ROALP (Relational OLAP)
관계형 데이터베이스를 기초로 한 OLAP 구조로 검색어 질의 처리에 드는 시간을 줄이기 위해 집계 테이블을 생성, 저장하여 두는 방식의 시스템
대량의 데이터 처리와 빠른 로딩, 원시 데이터 조회가 가능
HOLAP
ROLAP 와 MOLAP 의 특성을 모두 가지고 있는 OLAP 시스템 형태
Drill-down
분석할 항목에 대해 한 차원의 계층 구조를 따라 단계적으로 요약된 형태의 데이터로부터 구체적인 내용의 상세 데이터로 접근하는 기능
( <-> Roll-up)
Pivoting
보고서의 행, 열, 페이지 차원을 바꾸어 볼 수 있는 기능
Slicing
다차원 데이터 항목들을 다양한 각도에서 조회하고 자유롭게 비교하는 기능 (수직/수평으로 얇게 자름)
Dicing
Slicing을 더 쪼개는 기능 (주사위 모양으로 자름)
[출처] 정보처리기사 실기 데이터베이스 2011년 기출 정리|작성자 납땜천재
'직딩일기 > 자기계발' 카테고리의 다른 글
| React Fundermental 2019로 React App 만들기 2강~11강 (0) | 2020.10.04 |
|---|---|
| [정보처리기사/실기] SQL문 연습하기! (0) | 2017.08.28 |
| [정보처리기사/실기] 전산영어 요약 및 기출 (0) | 2017.08.28 |
| Mysql DB 한글깨짐 현상 해결 (0) | 2017.08.28 |
| [정보처리기사/실기] 업무프로세스 요약 및 기출 (0) | 2017.07.10 |